
En esta página, se describen los sistemas de compilación basados en tareas, su funcionamiento y algunas de las complicaciones que pueden ocurrir con estos sistemas. Después de las secuencias de comandos de shell, los sistemas de compilación basados en tareas son la siguiente evolución lógica de la compilación.
Comprende los sistemas de compilación basados en tareas
En un sistema de compilación basado en tareas, la unidad de trabajo fundamental es la tarea. Cada tarea es una secuencia de comandos que puede ejecutar cualquier tipo de lógica, y las tareas especifican otras tareas como dependencias que deben ejecutarse antes que ellas. La mayoría de los principales sistemas de compilación que se usan actualmente, como Ant, Maven, Gradle, Grunt y Rake, se basan en tareas. En lugar de secuencias de comandos de shell, la mayoría de los sistemas de compilación modernos requieren que los ingenieros creen archivos de compilación que describan cómo realizar la compilación.
Tomemos este ejemplo del manual de Ant:
<project name="MyProject" default="dist" basedir=".">
<description>
simple example build file
</description>
<!-- set global properties for this build -->
<property name="src" location="src"/>
<property name="build" location="build"/>
<property name="dist" location="dist"/>
<target name="init">
<!-- Create the time stamp -->
<tstamp/>
<!-- Create the build directory structure used by compile -->
<mkdir dir="${build}"/>
</target>
<target name="compile" depends="init"
description="compile the source">
<!-- Compile the Java code from ${src} into ${build} -->
<javac srcdir="${src}" destdir="${build}"/>
</target>
<target name="dist" depends="compile"
description="generate the distribution">
<!-- Create the distribution directory -->
<mkdir dir="${dist}/lib"/>
<!-- Put everything in ${build} into the MyProject-${DSTAMP}.jar file -->
<jar jarfile="${dist}/lib/MyProject-${DSTAMP}.jar" basedir="${build}"/>
</target>
<target name="clean"
description="clean up">
<!-- Delete the ${build} and ${dist} directory trees -->
<delete dir="${build}"/>
<delete dir="${dist}"/>
</target>
</project>
El archivo de compilación está escrito en XML y define algunos metadatos simples sobre la compilación junto con una lista de tareas (las etiquetas <target> en el XML). (Ant usa la palabra objetivo para representar una tarea y la palabra tarea para referirse a los comandos). Cada tarea ejecuta una lista de comandos posibles definidos por Ant, que aquí incluyen la creación y eliminación de directorios, la ejecución de javac y la creación de un archivo JAR. Este conjunto de comandos se puede extender con complementos proporcionados por el usuario para cubrir cualquier tipo de lógica. Cada tarea también puede definir las tareas de las que depende mediante el atributo de dependencias. Estas dependencias forman un grafo acíclico, como se ve en la Figura 1.
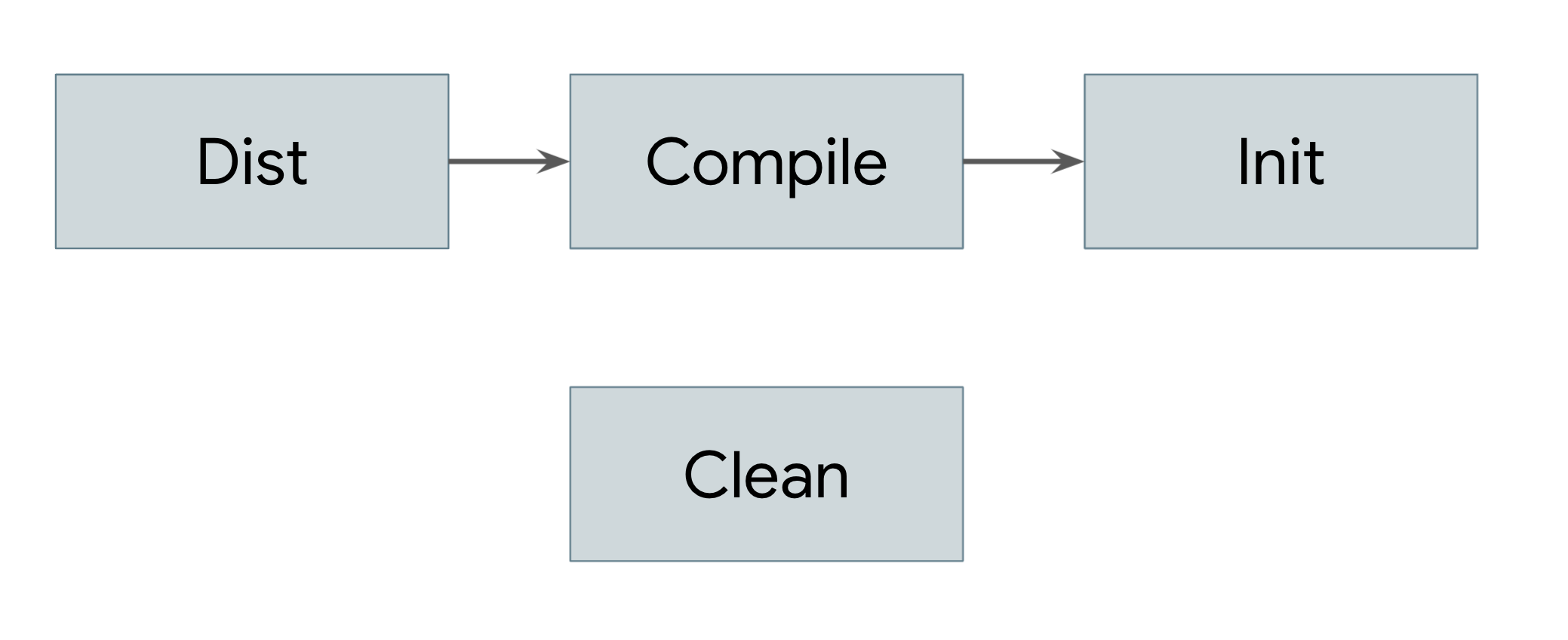
Figura 1: Un gráfico acíclico que muestra las dependencias
Los usuarios realizan compilaciones proporcionando tareas a la herramienta de línea de comandos de Ant. Por ejemplo, cuando un usuario escribe ant dist, Ant sigue los siguientes pasos:
- Carga un archivo llamado
build.xmlen el directorio actual y lo analiza para crear la estructura de grafo que se muestra en la Figura 1. - Busca la tarea llamada
distque se proporcionó en la línea de comandos y descubre que depende de la tarea llamadacompile. - Busca la tarea llamada
compiley descubre que tiene una dependencia en la tarea llamadainit. - Busca la tarea llamada
inity descubre que no tiene dependencias. - Ejecuta los comandos definidos en la tarea
init. - Ejecuta los comandos definidos en la tarea
compile, siempre que se hayan ejecutado todas las dependencias de esa tarea. - Ejecuta los comandos definidos en la tarea
distdado que se ejecutaron todas las dependencias de esa tarea.
Al final, el código que ejecuta Ant cuando ejecuta la tarea dist es equivalente a la siguiente secuencia de comandos de shell:
./createTimestamp.shmkdir build/javac src/* -d build/mkdir -p dist/lib/jar cf dist/lib/MyProject-$(date --iso-8601).jar build/*
Cuando se quita la sintaxis, el archivo de compilación y la secuencia de comandos de compilación no son demasiado diferentes. Pero ya ganamos mucho con esto. Podemos crear archivos de compilación nuevos en otros directorios y vincularlos. Podemos agregar tareas nuevas que dependen de tareas existentes de manera arbitraria y compleja con facilidad. Solo debemos pasar el nombre de una sola tarea a la herramienta de línea de comandos ant, y esta determina todo lo que se debe ejecutar.
Ant es una pieza de software antigua, que se lanzó originalmente en el año 2000. Otras herramientas, como Maven y Gradle, mejoraron Ant en los años anteriores y, básicamente, lo reemplazaron con funciones como la administración automática de dependencias externas y una sintaxis más limpia sin ningún XML. Sin embargo, la naturaleza de estos sistemas más nuevos sigue siendo la misma: permiten que los ingenieros escriban secuencias de comandos de compilación de manera modular y basada en principios como tareas, y proporcionan herramientas para ejecutar esas tareas y administrar las dependencias entre ellas.
El lado oscuro de los sistemas de compilación basados en tareas
Debido a que, en esencia, estas herramientas permiten que los ingenieros definan cualquier secuencia de comandos como una tarea, son muy potentes y te permiten hacer prácticamente todo lo que te imagines con ellas. Sin embargo, esa potencia trae desventajas, y puede resultar difícil trabajar con sistemas de compilación basados en tareas a medida que sus secuencias de comandos de compilación se vuelven más complejas. El problema con estos sistemas es que, en realidad, terminan dando demasiada autoridad a los ingenieros y no suficiente al sistema. Debido a que el sistema no tiene idea de lo que hacen las secuencias de comandos, el rendimiento se ve afectado, ya que debe ser muy conservador en la forma en que programa y ejecuta los pasos de compilación. Y el sistema no tiene forma de confirmar que cada secuencia de comandos esté haciendo lo que debería, por lo que las secuencias de comandos tienden a aumentar en complejidad y terminan siendo otra cosa que necesita depuración.
Dificultad para paralelizar los pasos de compilación
Las estaciones de trabajo de desarrollo modernas son bastante potentes, ya que cuentan con varios núcleos que pueden ejecutar varios pasos de compilación en paralelo. Sin embargo, los sistemas basados en tareas a menudo no pueden paralelizar la ejecución de tareas, incluso cuando parece que deberían poder hacerlo. Supongamos que la tarea A depende de las tareas B y C. Dado que las tareas B y C no dependen una de la otra, ¿es seguro ejecutarlas al mismo tiempo para que el sistema pueda llegar más rápido a la tarea A? o tal vez si no tocan ninguno de los mismos recursos. Pero tal vez no. Quizás ambos usan el mismo archivo para realizar un seguimiento de sus estados y ejecutarlos al mismo tiempo causa un conflicto. En general, el sistema no tiene forma de saberlo, por lo que debe arriesgarse a estos conflictos (lo que genera problemas de compilación poco frecuentes, pero muy difíciles de depurar) o debe restringir toda la compilación para que se ejecute en un solo subproceso en un solo proceso. Esto puede ser un gran desperdicio de una máquina potente para desarrolladores y descarta por completo la posibilidad de distribuir la compilación en varias máquinas.
Dificultad para realizar compilaciones incrementales
Un buen sistema de compilación permite que los ingenieros realicen compilaciones incrementales confiables, de modo que un pequeño cambio no requiera que se vuelva a compilar toda la base de código desde cero. Esto es muy importante si el sistema de compilación es lento y no puede paralelizar los pasos de compilación por los motivos antes mencionados. Sin embargo, lamentablemente, los sistemas de compilación basados en tareas también tienen dificultades aquí. Debido a que las tareas pueden hacer cualquier cosa, en general, no hay forma de verificar si ya se completaron. Muchas tareas simplemente toman un conjunto de archivos de origen y ejecutan un compilador para crear un conjunto de objetos binarios. Por lo tanto, no es necesario que se vuelvan a ejecutar si los archivos fuente subyacentes no cambiaron. Sin embargo, sin información adicional, el sistema no puede afirmarlo con seguridad. Quizás la tarea descargue un archivo que podría haber cambiado o quizás escriba una marca de tiempo que podría ser diferente en cada ejecución. Para garantizar la exactitud, el sistema suele tener que volver a ejecutar cada tarea durante cada compilación. Algunos sistemas de compilación intentan habilitar las compilaciones incrementales permitiendo que los ingenieros especifiquen las condiciones en las que una tarea debe volver a ejecutarse. A veces es posible, pero suele ser un problema mucho más complicado de lo que parece. Por ejemplo, en lenguajes como C++, que permiten que otros archivos incluyan archivos directamente, es imposible determinar todo el conjunto de archivos que se deben supervisar en busca de cambios sin analizar las fuentes de entrada. A menudo, los ingenieros terminan tomando atajos, y estos atajos pueden generar problemas poco comunes y frustrantes en los que se reutiliza un resultado de tarea incluso cuando no debería ser así. Cuando esto sucede con frecuencia, los ingenieros adquieren el hábito de ejecutar una limpieza antes de cada compilación para obtener un estado nuevo, lo que anula por completo el propósito de tener una compilación incremental en primer lugar. Descubrir cuándo se debe volver a ejecutar una tarea es sorprendentemente sutil y es una tarea que las máquinas manejan mejor que las personas.
Dificultad para mantener y depurar secuencias de comandos
Por último, las secuencias de comandos de compilación que imponen los sistemas de compilación basados en tareas a menudo son difíciles de usar. Aunque a menudo reciben menos escrutinio, las secuencias de comandos de compilación son código, al igual que el sistema que se compila, y son lugares fáciles para que se oculten los errores. A continuación, se incluyen algunos ejemplos de errores muy comunes cuando se trabaja con un sistema de compilación basado en tareas:
- La tarea A depende de la tarea B para producir un archivo en particular como resultado. El propietario de la tarea B no se da cuenta de que otras tareas dependen de ella, por lo que la cambia para producir resultados en una ubicación diferente. Esto no se puede detectar hasta que alguien intente ejecutar la tarea A y encuentre que falla.
- La tarea A depende de la tarea B, que depende de la tarea C, que produce un archivo en particular como resultado necesario para la tarea A. El propietario de la tarea B decide que ya no necesita depender de la tarea C, lo que hace que la tarea A falle, aunque a la tarea B no le importa en absoluto la tarea C.
- El desarrollador de una tarea nueva hace una suposición accidental sobre la máquina que ejecuta la tarea, como la ubicación de una herramienta o el valor de variables de entorno particulares. La tarea funciona en su máquina, pero falla cuando otro desarrollador la prueba.
- Una tarea contiene un componente no determinista, como descargar un archivo de Internet o agregar una marca de tiempo a una compilación. Ahora, las personas obtienen resultados potencialmente diferentes cada vez que ejecutan la compilación, lo que significa que los ingenieros no siempre podrán reproducir y corregir las fallas de los demás que ocurran en un sistema de compilación automatizado.
- Las tareas con varias dependencias pueden crear condiciones de carrera. Si la tarea A depende de las tareas B y C, y las tareas B y C modifican el mismo archivo, la tarea A obtiene un resultado diferente según cuál de las tareas B y C finaliza primero.
No existe una forma de uso general de resolver estos problemas de rendimiento, corrección o mantenimiento dentro del framework basado en tareas que se describe aquí. Mientras los ingenieros puedan escribir código arbitrario que se ejecute durante la compilación, el sistema no puede tener suficiente información para poder ejecutar compilaciones de forma rápida y correcta. Para resolver el problema, debemos quitar algo de poder de las manos de los ingenieros, volver a ponerlo en manos del sistema y reconceptualizar la función del sistema, no como tareas en ejecución, sino como producción.
Este enfoque condujo a la creación de sistemas de compilación basados en artefactos, como Blaze y Bazel.