
如果程式碼集很大,依附元件鏈可能會非常深。即使是簡單的二進位檔,也可能需要數萬個建構目標。在這個規模下,單一機器根本不可能在合理的時間內完成建構作業:沒有任何建構系統可以規避機器硬體的基本物理定律。如要達成這個目標,唯一的方法是使用支援分散式建構的建構系統,讓系統執行的工作單元分散到任意數量的可擴充機器上。假設我們已將系統工作劃分為足夠小的單元 (稍後會詳細說明),這可讓我們以願意支付的費用,盡快完成任何大小的建構作業。我們定義以構件為基礎的建構系統,就是為了實現這種擴充性。
遠端快取
最簡單的分散式建構類型是只運用遠端快取,如圖 1 所示。
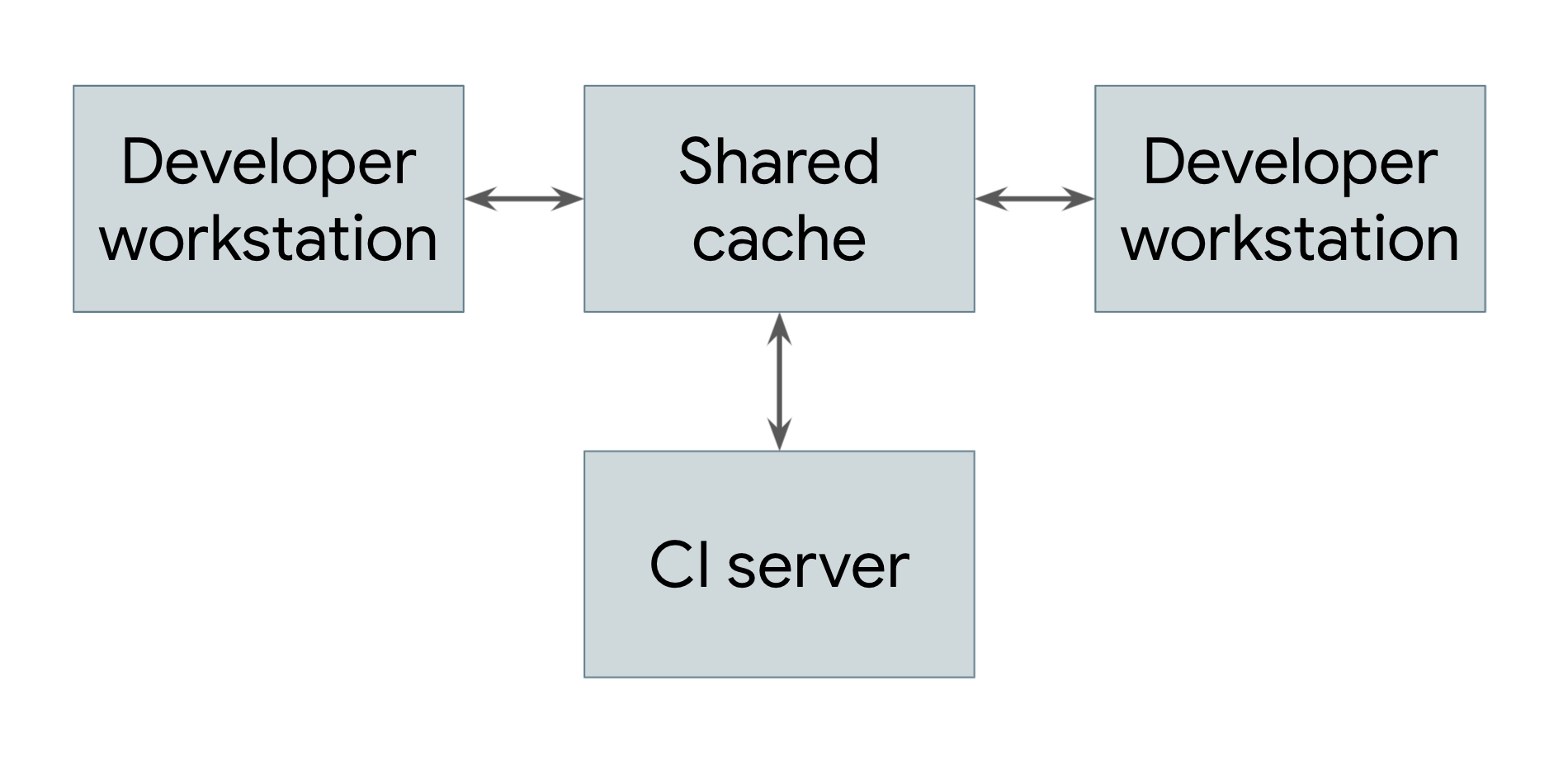
圖 1. 顯示遠端快取的分散式建構
執行建構作業的每個系統 (包括開發人員工作站和持續整合系統) 都會共用通用遠端快取服務的參照。這項服務可以是 Redis 等快速的本機短期儲存系統,也可以是 Google Cloud Storage 等雲端服務。每當使用者需要建構構件 (無論是直接建構或做為依附元件),系統都會先檢查遠端快取,確認該構件是否已存在。如果是,系統可以下載構件,不必建構。如果沒有,系統會自行建構構件,並將結果上傳回快取。也就是說,不常變更的低階依附元件可以建構一次,並在使用者之間共用,不必由每位使用者重建。在 Google,許多構件都是從快取提供,而非從頭建構,因此大幅降低了建構系統的執行成本。
如要讓遠端快取系統運作,建構系統必須確保建構作業完全可重現。也就是說,對於任何建構目標,都必須能夠判斷該目標的輸入集,這樣一來,在任何機器上,相同的輸入集都會產生完全相同的輸出內容。這是確保下載構件的結果與自行建構結果相同的唯一方法。請注意,這項作業需要以目標和輸入內容的雜湊值為快取中的每個構件建立索引,這樣一來,不同工程師就能同時對相同目標進行不同修改,而遠端快取會儲存所有產生的構件,並適當提供這些構件,不會發生衝突。
當然,如要從遠端快取獲得任何好處,下載構件的速度必須比建構構件更快。但並非一律如此,尤其是當快取伺服器與執行建構作業的機器相距甚遠時。Google 的網路和建構系統經過仔細調整,可快速分享建構結果。
遠端執行
遠端快取並非真正的分散式建構作業。如果快取遺失,或是您進行低階變更,導致所有內容都必須重建,您仍需在本機上執行完整建構作業。真正的目標是支援遠端執行,讓建構的實際工作可分散到任意數量的工作站。圖 2 顯示遠端執行系統。
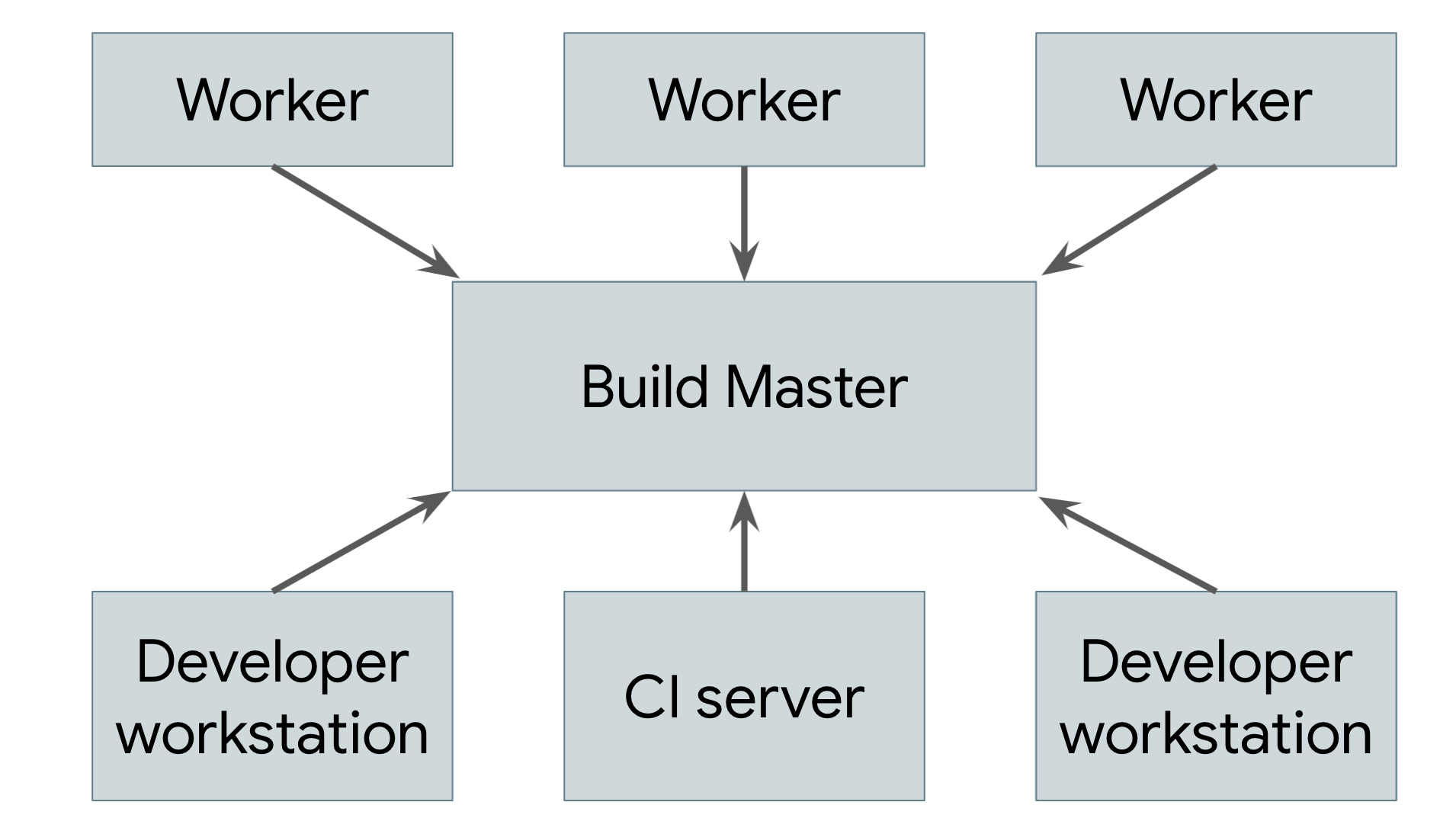
圖 2. 遠端執行系統
在每位使用者的電腦上執行的建構工具 (使用者可以是工程師或自動化建構系統) 會將要求傳送至中央建構主機。建構主機將要求分解為元件動作,並排定這些動作在可擴充的工作站集區中執行。每個工作人員都會根據使用者指定的輸入內容執行要求動作,並寫出產生的構件。這些構件會與執行需要這些構件的動作的其他機器共用,直到產生最終輸出內容並傳送給使用者為止。
實作這類系統最棘手的部分,就是管理工作者、主機和使用者本機之間的通訊。Worker 可能會依附於其他 Worker 產生的中繼構件,且最終輸出內容必須傳回使用者的本機。為此,我們可以根據先前所述的分散式快取,讓每個工作人員將結果寫入快取,並從快取讀取其依附元件。主節點會封鎖工作人員,直到所有依附項目完成為止,屆時工作人員就能從快取讀取輸入內容。最終產品也會快取,方便本機下載。請注意,我們也需要另外匯出使用者來源樹狀結構中的本機變更,以便工作人員在建構前套用這些變更。
如要讓這項功能運作,必須整合先前所述的構件式建構系統所有部分。建構環境必須完全自我描述,我們才能在不需人為介入的情況下啟動工作人員。建構程序本身必須完全獨立,因為每個步驟都可能在不同的機器上執行。輸出內容必須完全具決定性,這樣每個工作站才能信任從其他工作站收到的結果。以工作為基礎的系統極難提供這類保證,因此幾乎不可能在這種系統上建構可靠的遠端執行系統。
Google 的分散式建構作業
自 2008 年起,Google 就開始使用分散式建構系統,同時採用遠端快取和遠端執行,如圖 3 所示。
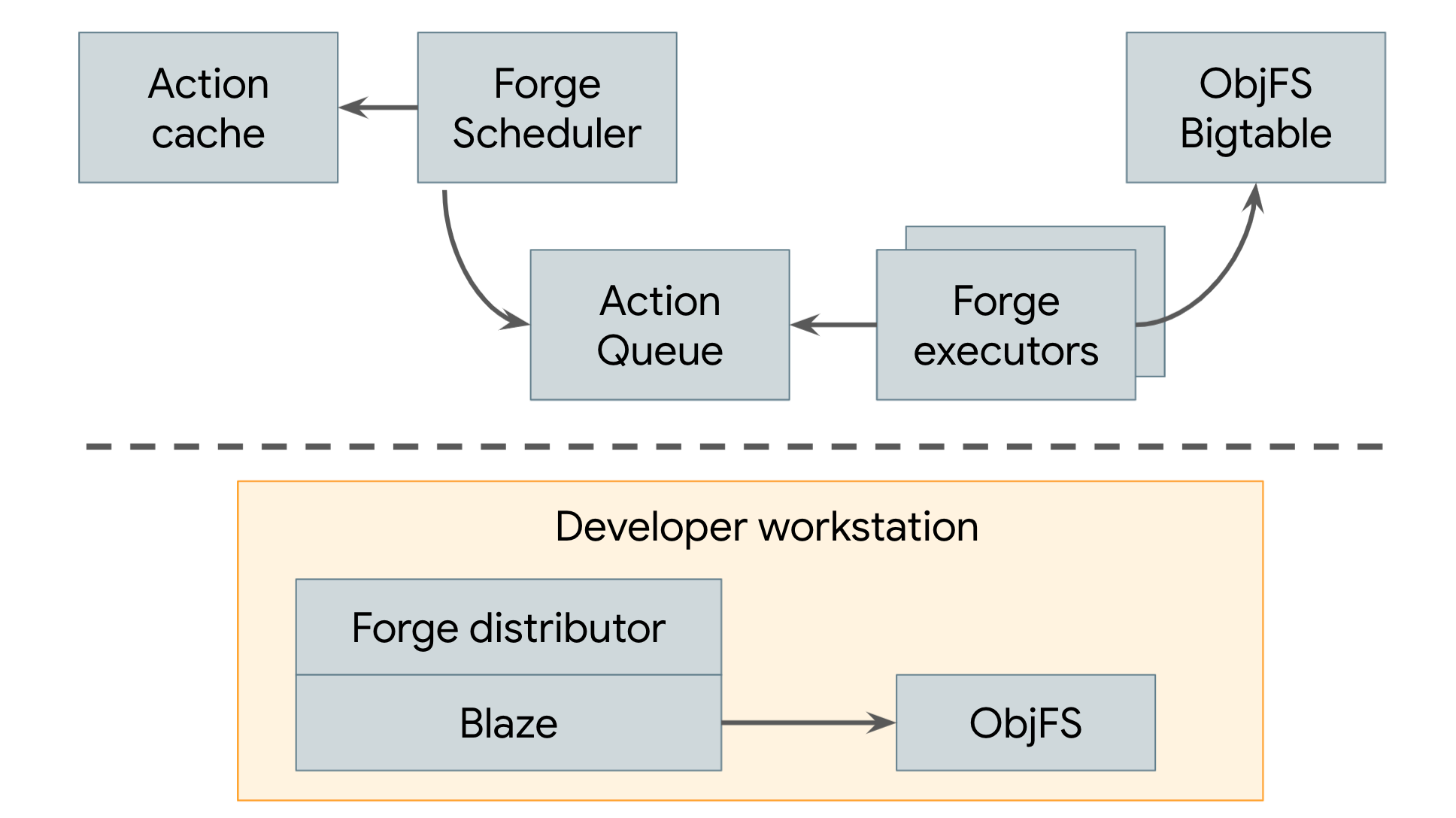
圖 3. Google 的分散式建構系統
Google 的遠端快取稱為 ObjFS。這個系統由後端和前端組成,後端會將建構輸出內容儲存在 Bigtable 中,並分散到整個生產機器機群,前端則是在每部開發人員機器上執行的 FUSE 精靈,名稱為 objfsd。工程師可透過 FUSE 精靈瀏覽建構輸出內容,就像瀏覽儲存在工作站上的正常檔案一樣,但只有使用者直接要求的少數檔案,才會視需要下載檔案內容。視需要提供檔案內容可大幅減少網路和磁碟用量,與將所有建構輸出內容儲存在開發人員本機磁碟的情況相比,系統建構速度可快上一倍。
Google 的遠端執行系統稱為 Forge。Blaze (Bazel 的內部對等項目) 中的 Forge 用戶端會呼叫 Distributor,並將每個動作的要求傳送至資料中心執行的作業 (稱為「排程器」)。排程器會維護動作結果的快取,因此如果系統的其他使用者已建立動作,排程器就能立即傳回回應。如果沒有,系統會將動作放入佇列。大量的執行器工作會持續從這個佇列讀取動作、執行動作,並將結果直接儲存在 ObjFS Bigtable 中。這些結果可供執行者用於日後動作,或由使用者透過 objfsd 下載。
最終成果是可擴充的系統,能有效支援 Google 執行的所有建構作業。Google 的建構規模非常龐大:Google 每天執行數百萬次建構,執行數百萬個測試案例,並從數十億行的原始碼產生數千兆位元組的建構輸出內容。這類系統不僅能讓工程師快速建構複雜的程式碼集,還能實作大量依賴建構作業的自動化工具和系統。