
This page covers task-based build systems, how they work and some of the complications that can occur with task-based systems. After shell scripts, task-based build systems are the next logical evolution of building.
Understanding task-based build systems
In a task-based build system, the fundamental unit of work is the task. Each task is a script that can execute any sort of logic, and tasks specify other tasks as dependencies that must run before them. Most major build systems in use today, such as Ant, Maven, Gradle, Grunt, and Rake, are task based. Instead of shell scripts, most modern build systems require engineers to create build files that describe how to perform the build.
Take this example from the Ant manual:
<project name="MyProject" default="dist" basedir=".">
<description>
simple example build file
</description>
<!-- set global properties for this build -->
<property name="src" location="src"/>
<property name="build" location="build"/>
<property name="dist" location="dist"/>
<target name="init">
<!-- Create the time stamp -->
<tstamp/>
<!-- Create the build directory structure used by compile -->
<mkdir dir="${build}"/>
</target>
<target name="compile" depends="init"
description="compile the source">
<!-- Compile the Java code from ${src} into ${build} -->
<javac srcdir="${src}" destdir="${build}"/>
</target>
<target name="dist" depends="compile"
description="generate the distribution">
<!-- Create the distribution directory -->
<mkdir dir="${dist}/lib"/>
<!-- Put everything in ${build} into the MyProject-${DSTAMP}.jar file -->
<jar jarfile="${dist}/lib/MyProject-${DSTAMP}.jar" basedir="${build}"/>
</target>
<target name="clean"
description="clean up">
<!-- Delete the ${build} and ${dist} directory trees -->
<delete dir="${build}"/>
<delete dir="${dist}"/>
</target>
</project>
The buildfile is written in XML and defines some simple metadata about the build
along with a list of tasks (the <target> tags in the XML). (Ant uses the word
target to represent a task, and it uses the word task to refer to
commands.) Each task executes a list of possible commands defined by Ant,
which here include creating and deleting directories, running javac, and
creating a JAR file. This set of commands can be extended by user-provided
plug-ins to cover any sort of logic. Each task can also define the tasks it
depends on via the depends attribute. These dependencies form an acyclic graph,
as seen in Figure 1.
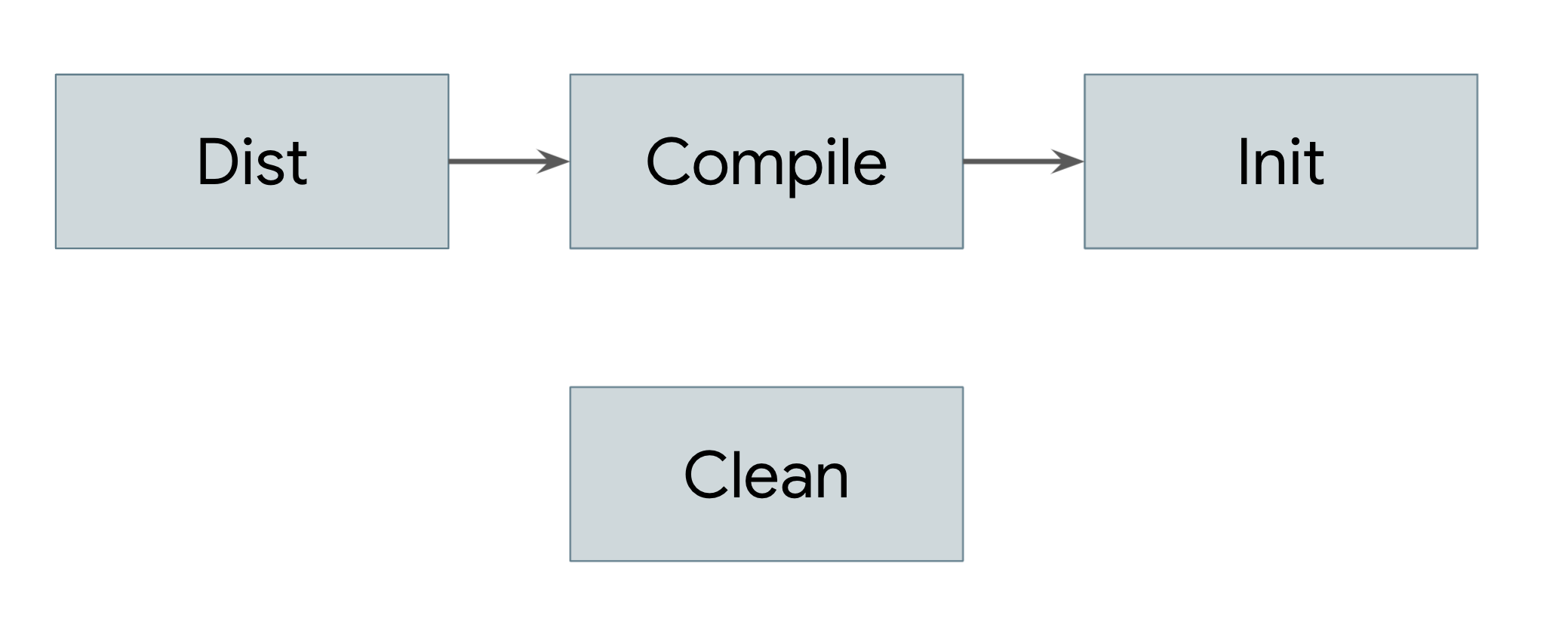
Figure 1. An acyclic graph showing dependencies
Users perform builds by providing tasks to Ant’s command-line tool. For example,
when a user types ant dist, Ant takes the following steps:
- Loads a file named
build.xmlin the current directory and parses it to create the graph structure shown in Figure 1. - Looks for the task named
distthat was provided on the command line and discovers that it has a dependency on the task namedcompile. - Looks for the task named
compileand discovers that it has a dependency on the task namedinit. - Looks for the task named
initand discovers that it has no dependencies. - Executes the commands defined in the
inittask. - Executes the commands defined in the
compiletask given that all of that task’s dependencies have been run. - Executes the commands defined in the
disttask given that all of that task’s dependencies have been run.
In the end, the code executed by Ant when running the dist task is equivalent
to the following shell script:
./createTimestamp.shmkdir build/javac src/* -d build/mkdir -p dist/lib/jar cf dist/lib/MyProject-$(date --iso-8601).jar build/*
When the syntax is stripped away, the buildfile and the build script actually
aren’t too different. But we’ve already gained a lot by doing this. We can
create new buildfiles in other directories and link them together. We can easily
add new tasks that depend on existing tasks in arbitrary and complex ways. We
need only pass the name of a single task to the ant command-line tool, and it
determines everything that needs to be run.
Ant is an old piece of software, originally released in 2000. Other tools like Maven and Gradle have improved on Ant in the intervening years and essentially replaced it by adding features like automatic management of external dependencies and a cleaner syntax without any XML. But the nature of these newer systems remains the same: they allow engineers to write build scripts in a principled and modular way as tasks and provide tools for executing those tasks and managing dependencies among them.
The dark side of task-based build systems
Because these tools essentially let engineers define any script as a task, they are extremely powerful, allowing you to do pretty much anything you can imagine with them. But that power comes with drawbacks, and task-based build systems can become difficult to work with as their build scripts grow more complex. The problem with such systems is that they actually end up giving too much power to engineers and not enough power to the system. Because the system has no idea what the scripts are doing, performance suffers, as it must be very conservative in how it schedules and executes build steps. And there’s no way for the system to confirm that each script is doing what it should, so scripts tend to grow in complexity and end up being another thing that needs debugging.
Difficulty of parallelizing build steps
Modern development workstations are quite powerful, with multiple cores that are capable of executing several build steps in parallel. But task-based systems are often unable to parallelize task execution even when it seems like they should be able to. Suppose that task A depends on tasks B and C. Because tasks B and C have no dependency on each other, is it safe to run them at the same time so that the system can more quickly get to task A? Maybe, if they don’t touch any of the same resources. But maybe not—perhaps both use the same file to track their statuses and running them at the same time causes a conflict. There’s no way in general for the system to know, so either it has to risk these conflicts (leading to rare but very difficult-to-debug build problems), or it has to restrict the entire build to running on a single thread in a single process. This can be a huge waste of a powerful developer machine, and it completely rules out the possibility of distributing the build across multiple machines.
Difficulty performing incremental builds
A good build system allows engineers to perform reliable incremental builds such that a small change doesn’t require the entire codebase to be rebuilt from scratch. This is especially important if the build system is slow and unable to parallelize build steps for the aforementioned reasons. But unfortunately, task-based build systems struggle here, too. Because tasks can do anything, there’s no way in general to check whether they’ve already been done. Many tasks simply take a set of source files and run a compiler to create a set of binaries; thus, they don’t need to be rerun if the underlying source files haven’t changed. But without additional information, the system can’t say this for sure—maybe the task downloads a file that could have changed, or maybe it writes a timestamp that could be different on each run. To guarantee correctness, the system typically must rerun every task during each build. Some build systems try to enable incremental builds by letting engineers specify the conditions under which a task needs to be rerun. Sometimes this is feasible, but often it’s a much trickier problem than it appears. For example, in languages like C++ that allow files to be included directly by other files, it’s impossible to determine the entire set of files that must be watched for changes without parsing the input sources. Engineers often end up taking shortcuts, and these shortcuts can lead to rare and frustrating problems where a task result is reused even when it shouldn’t be. When this happens frequently, engineers get into the habit of running clean before every build to get a fresh state, completely defeating the purpose of having an incremental build in the first place. Figuring out when a task needs to be rerun is surprisingly subtle, and is a job better handled by machines than humans.
Difficulty maintaining and debugging scripts
Finally, the build scripts imposed by task-based build systems are often just difficult to work with. Though they often receive less scrutiny, build scripts are code just like the system being built, and are easy places for bugs to hide. Here are some examples of bugs that are very common when working with a task-based build system:
- Task A depends on task B to produce a particular file as output. The owner of task B doesn’t realize that other tasks rely on it, so they change it to produce output in a different location. This can’t be detected until someone tries to run task A and finds that it fails.
- Task A depends on task B, which depends on task C, which is producing a particular file as output that’s needed by task A. The owner of task B decides that it doesn’t need to depend on task C any more, which causes task A to fail even though task B doesn’t care about task C at all!
- The developer of a new task accidentally makes an assumption about the machine running the task, such as the location of a tool or the value of particular environment variables. The task works on their machine, but fails whenever another developer tries it.
- A task contains a nondeterministic component, such as downloading a file from the internet or adding a timestamp to a build. Now, people get potentially different results each time they run the build, meaning that engineers won’t always be able to reproduce and fix one another’s failures or failures that occur on an automated build system.
- Tasks with multiple dependencies can create race conditions. If task A depends on both task B and task C, and task B and C both modify the same file, task A gets a different result depending on which one of tasks B and C finishes first.
There’s no general-purpose way to solve these performance, correctness, or maintainability problems within the task-based framework laid out here. So long as engineers can write arbitrary code that runs during the build, the system can’t have enough information to always be able to run builds quickly and correctly. To solve the problem, we need to take some power out of the hands of engineers and put it back in the hands of the system and reconceptualize the role of the system not as running tasks, but as producing artifacts.
This approach led to the creation of artifact-based build systems, like Blaze and Bazel.