
如果代码库很大,依赖项链可能会非常深。即使是简单的二进制文件,也常常依赖于数万个 build 目标。在这种规模下,在单台机器上根本无法在合理的时间内完成 build:任何构建系统都无法绕过机器硬件所受的基本物理定律。要实现此目的,唯一的方法是使用支持分布式构建的构建系统,其中系统执行的工作单元分布在任意数量的可扩容机器上。假设我们已将系统的工作分解为足够小的单元(稍后会详细介绍),这样一来,我们就可以根据自己的预算,尽可能快速地完成任何规模的 build。这种可伸缩性是我们通过定义基于制品的构建系统一直努力实现的目标。
远程缓存
最简单的分布式 build 是仅利用远程缓存的 build,如图 1 所示。
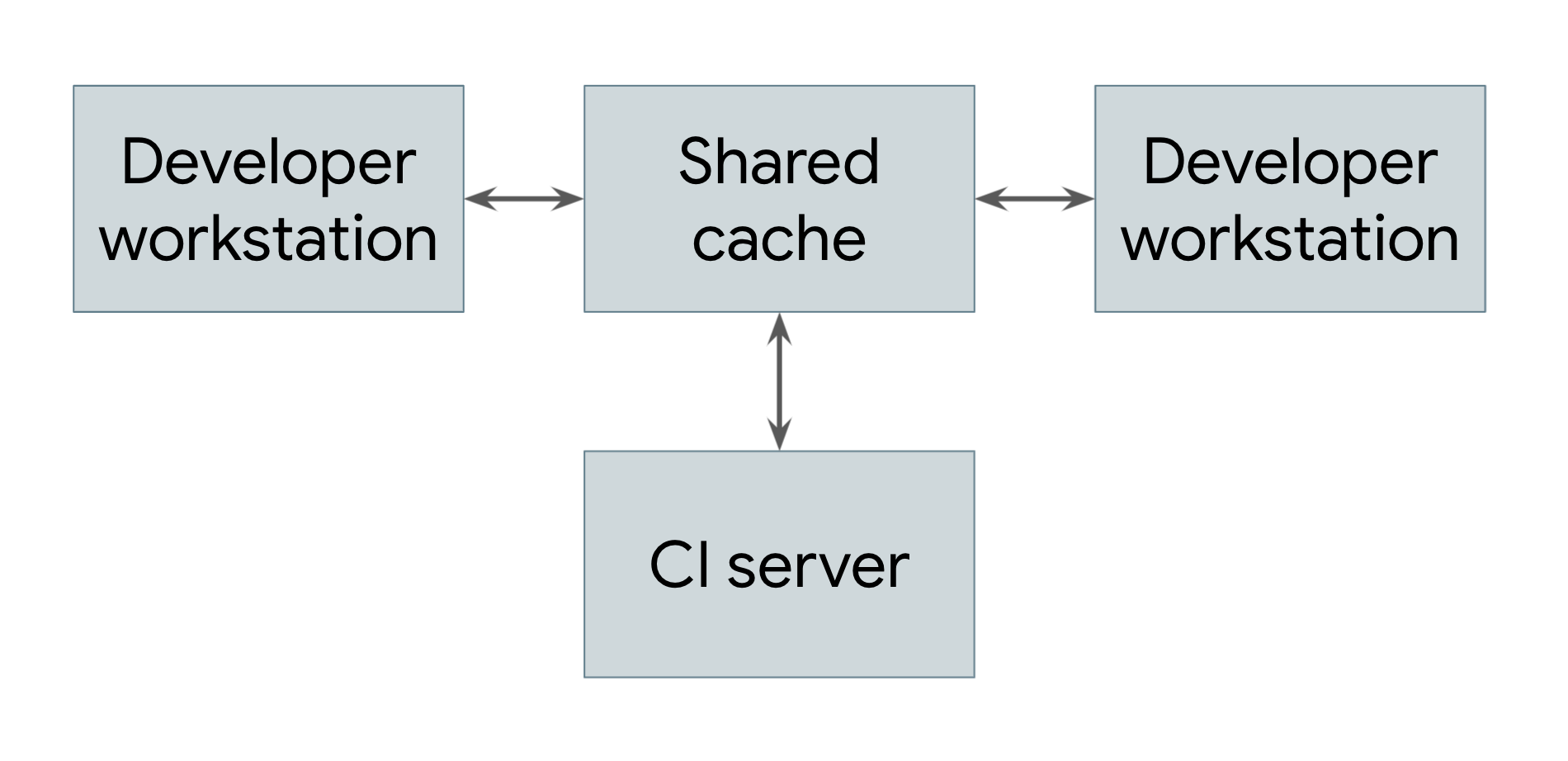
图 1. 显示远程缓存的分布式 build
执行 build 的每个系统(包括开发者工作站和持续集成系统)都共享对通用远程缓存服务的引用。此服务可以是 Redis 等快速的本地短期存储系统,也可以是 Google Cloud Storage 等云服务。每当用户需要构建制品时(无论是直接构建还是作为依赖项构建),系统都会先检查远程缓存,看看该制品是否已存在于其中。如果是,则可以下载制品,而不是构建制品。如果不存在,系统会自行构建制品,并将结果上传回缓存。这意味着,不经常更改的低级依赖项可以构建一次并跨用户共享,而无需由每个用户重新构建。在 Google,许多制品都是从缓存中提供,而不是从头构建,这大大降低了运行构建系统的成本。
为了使远程缓存系统正常运行,构建系统必须保证 build 完全可重现。也就是说,对于任何 build 目标,都必须能够确定该目标的输入集,以便同一组输入在任何机器上都能生成完全相同的输出。这是确保下载工件的结果与自行构建工件的结果相同的唯一方法。请注意,这要求缓存中的每个制品都以其目标和输入内容的哈希为键。这样一来,不同的工程师就可以同时对同一目标进行不同的修改,而远程缓存会存储所有生成的制品,并以适当的方式提供这些制品,不会发生冲突。
当然,要从远程缓存中获益,下载制品的速度必须快于构建制品的速度。但情况并非总是如此,尤其是在缓存服务器距离执行 build 的机器很远时。Google 的网络和构建系统经过精心调整,能够快速共享构建结果。
远程执行
远程缓存并非真正的分布式构建。如果缓存丢失,或者您进行了需要重新构建所有内容的低级别更改,您仍然需要在本地机器上执行整个构建。真正的目标是支持远程执行,这样一来,构建的实际工作就可以分布在任意数量的工作器上。图 2 描绘了一个远程执行系统。
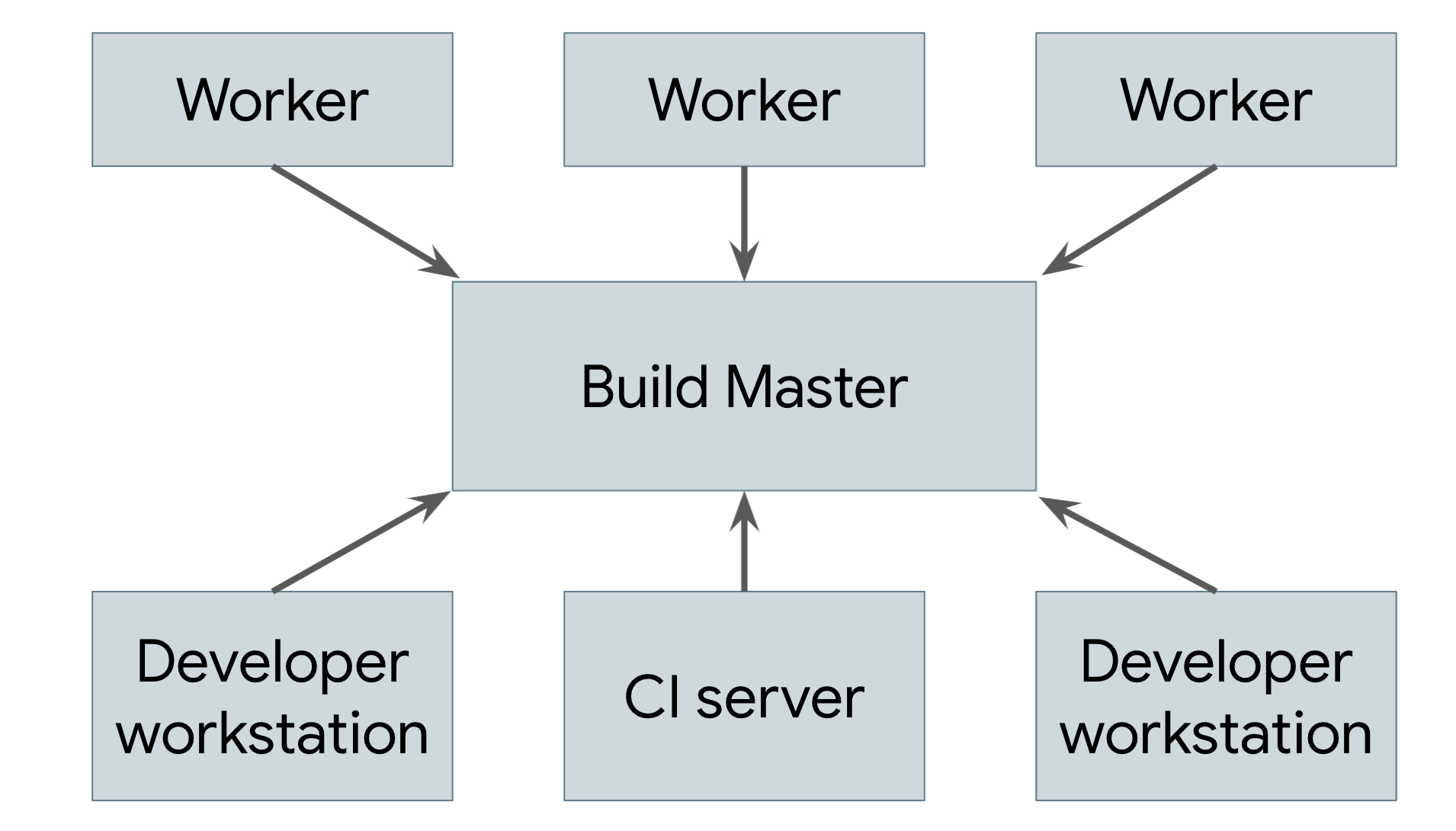
图 2. 远程执行系统
在每位用户的机器上(用户可以是人工工程师,也可以是自动化构建系统)运行的构建工具会向中央构建主节点发送请求。构建主服务器将请求分解为组成操作,并安排在可扩缩的工作器池中执行这些操作。每个 worker 都会根据用户指定的输入执行要求其执行的操作,并写出生成的制品。这些制品在执行需要它们的其他机器之间共享,直到可以生成最终输出并将其发送给用户。
实现此类系统最棘手的部分是管理工作器、主实例和用户本地机器之间的通信。工作器可能依赖于其他工作器生成的中间制品,并且最终输出需要发送回用户的本地机器。为此,我们可以基于前面介绍的分布式缓存,让每个工作器将其结果写入缓存并从缓存中读取其依赖项。主节点会阻止工作节点继续执行,直到它们依赖的所有内容都已完成,在这种情况下,它们将能够从缓存中读取输入。最终产品也会被缓存,以便本地机器下载。请注意,我们还需要一种单独的方法来导出用户源代码树中的本地更改,以便工作人员可以在构建之前应用这些更改。
为此,之前介绍的基于制品的 build 系统的所有部分都需要结合在一起。构建环境必须完全自描述,以便我们可以在无人为干预的情况下启动工作器。构建流程本身必须完全自成一体,因为每个步骤都可能在不同的机器上执行。输出必须完全确定,以便每个工作器都能信任从其他工作器收到的结果。基于任务的系统很难提供此类保证,因此几乎不可能在其基础上构建可靠的远程执行系统。
Google 的分布式 build
自 2008 年以来,Google 一直使用采用远程缓存和远程执行的分布式构建系统,如图 3 所示。
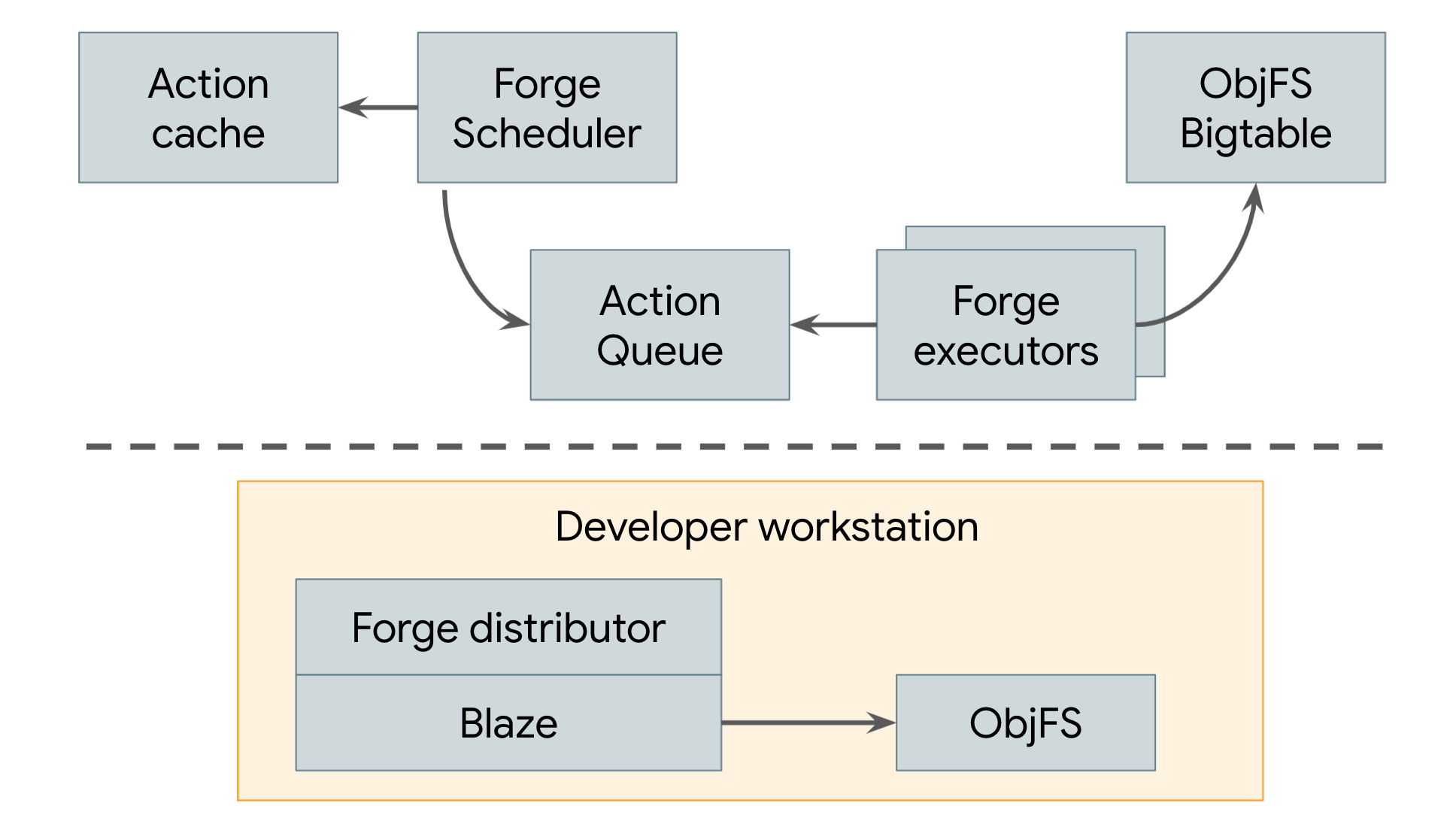
图 3. Google 的分布式构建系统
Google 的远程缓存称为 ObjFS。它由一个后端组成,该后端将 build 输出存储在分布于我们生产环境机器群中的 Bigtable 中;它还包含一个前端 FUSE 守护程序,名为 objfsd,在每位开发者的机器上运行。借助 FUSE 守护程序,工程师可以像浏览工作站上存储的普通文件一样浏览 build 输出,但文件内容仅在用户直接请求时才按需下载。按需提供文件内容可大幅减少网络和磁盘使用量,并且与将所有 build 输出存储在开发者的本地磁盘上相比,系统能够以两倍的速度进行 build。
Google 的远程执行系统称为 Forge。Blaze(Bazel 的内部等效项)中的 Forge 客户端(称为 Distributor)会针对每个操作向数据中心内运行的作业(称为 Scheduler)发送请求。调度程序会维护操作结果缓存,以便在系统的任何其他用户已创建操作的情况下立即返回响应。如果不是,则将该操作放入队列中。大量执行器作业会不断从该队列中读取操作、执行这些操作,并将结果直接存储在 ObjFS Bigtable 中。这些结果可供执行者用于后续操作,也可供最终用户通过 objfsd 下载。
最终,我们构建了一个可扩缩的系统,能够高效支持 Google 执行的所有 build。Google 的 build 规模非常庞大:Google 每天运行数百万个 build,执行数百万个测试用例,并从数十亿行源代码中生成 PB 级的 build 输出。此类系统不仅可让我们的工程师快速构建复杂的代码库,还可让我们实现大量依赖于我们 build 的自动化工具和系统。