The parallel evaluation and incrementality model of Bazel.
Data model
The data model consists of the following items:
SkyValue. Also called nodes.SkyValuesare immutable objects that contain all the data built over the course of the build and the inputs of the build. Examples are: input files, output files, targets and configured targets.SkyKey. A short immutable name to reference aSkyValue, for example,FILECONTENTS:/tmp/fooorPACKAGE://foo.SkyFunction. Builds nodes based on their keys and dependent nodes.- Node graph. A data structure containing the dependency relationship between nodes.
Skyframe. Code name for the incremental evaluation framework Bazel is based on.
Evaluation
A build is achieved by evaluating the node that represents the build request.
First, Bazel finds the SkyFunction corresponding to the key of the top-level
SkyKey. The function then requests the evaluation of the nodes it needs to
evaluate the top-level node, which in turn result in other SkyFunction calls,
until the leaf nodes are reached. Leaf nodes are usually ones that represent
input files in the file system. Finally, Bazel ends up with the value of the
top-level SkyValue, some side effects (such as output files in the file
system) and a directed acyclic graph of the dependencies between the nodes
involved in the build.
A SkyFunction can request SkyKeys in multiple passes if it cannot tell in
advance all of the nodes it needs to do its job. A simple example is evaluating
an input file node that turns out to be a symlink: the function tries to read
the file, realizes that it is a symlink, and thus fetches the file system node
representing the target of the symlink. But that itself can be a symlink, in
which case the original function will need to fetch its target, too.
The functions are represented in the code by the interface SkyFunction and the
services provided to it by an interface called SkyFunction.Environment. These
are the things functions can do:
- Request the evaluation of another node by way of calling
env.getValue. If the node is available, its value is returned, otherwise,nullis returned and the function itself is expected to returnnull. In the latter case, the dependent node is evaluated, and then the original node builder is invoked again, but this time the sameenv.getValuecall will return a non-nullvalue. - Request the evaluation of multiple other nodes by calling
env.getValues(). This does essentially the same, except that the dependent nodes are evaluated in parallel. - Do computation during their invocation
- Have side effects, for example, writing files to the file system. Care needs to be taken that two different functions avoid stepping on each other's toes. In general, write side effects (where data flows outwards from Bazel) are okay, read side effects (where data flows inwards into Bazel without a registered dependency) are not, because they are an unregistered dependency and as such, can cause incorrect incremental builds.
Well-behaved SkyFunction implementations avoid accessing data in any other way
than requesting dependencies (such as by directly reading the file system),
because that results in Bazel not registering the data dependency on the file
that was read, thus resulting in incorrect incremental builds.
Once a function has enough data to do its job, it should return a non-null
value indicating completion.
This evaluation strategy has a number of benefits:
- Hermeticity. If functions only request input data by way of depending on other nodes, Bazel can guarantee that if the input state is the same, the same data is returned. If all sky functions are deterministic, this means that the whole build will also be deterministic.
- Correct and perfect incrementality. If all the input data of all functions is recorded, Bazel can invalidate only the exact set of nodes that need to be invalidated when the input data changes.
- Parallelism. Since functions can only interact with each other by way of requesting dependencies, functions that don't depend on each other can be run in parallel and Bazel can guarantee that the result is the same as if they were run sequentially.
Incrementality
Since functions can only access input data by depending on other nodes, Bazel can build up a complete data flow graph from the input files to the output files, and use this information to only rebuild those nodes that actually need to be rebuilt: the reverse transitive closure of the set of changed input files.
In particular, two possible incrementality strategies exist: the bottom-up one and the top-down one. Which one is optimal depends on how the dependency graph looks like.
During bottom-up invalidation, after a graph is built and the set of changed inputs is known, all the nodes are invalidated that transitively depend on changed files. This is optimal if the same top-level node will be built again. Note that bottom-up invalidation requires running
stat()on all input files of the previous build to determine if they were changed. This can be improved by usinginotifyor a similar mechanism to learn about changed files.During top-down invalidation, the transitive closure of the top-level node is checked and only those nodes are kept whose transitive closure is clean. This is better if the node graph is large, but the next build only needs a small subset of it: bottom-up invalidation would invalidate the larger graph of the first build, unlike top-down invalidation, which just walks the small graph of second build.
Bazel only does bottom-up invalidation.
To get further incrementality, Bazel uses change pruning: if a node is invalidated, but upon rebuild, it is discovered that its new value is the same as its old value, the nodes that were invalidated due to a change in this node are "resurrected".
This is useful, for example, if one changes a comment in a C++ file: then the
.o file generated from it will be the same, thus, it is unnecessary to call
the linker again.
Incremental Linking / Compilation
The main limitation of this model is that the invalidation of a node is an all-or-nothing affair: when a dependency changes, the dependent node is always rebuilt from scratch, even if a better algorithm would exist that would mutate the old value of the node based on the changes. A few examples where this would be useful:
- Incremental linking
- When a single class file changes in a JAR file, it is possible modify the JAR file in-place instead of building it from scratch again.
The reason why Bazel does not support these things in a principled way is twofold:
- There were limited performance gains.
- Difficulty to validate that the result of the mutation is the same as that of a clean rebuild would be, and Google values builds that are bit-for-bit repeatable.
Until now, it was possible to achieve good enough performance by decomposing an expensive build step and achieving partial re-evaluation that way. For example, in an Android app, you can split all the classes into multiple groups and dex them separately. This way, if classes in a group are unchanged, the dexing does not have to be redone.
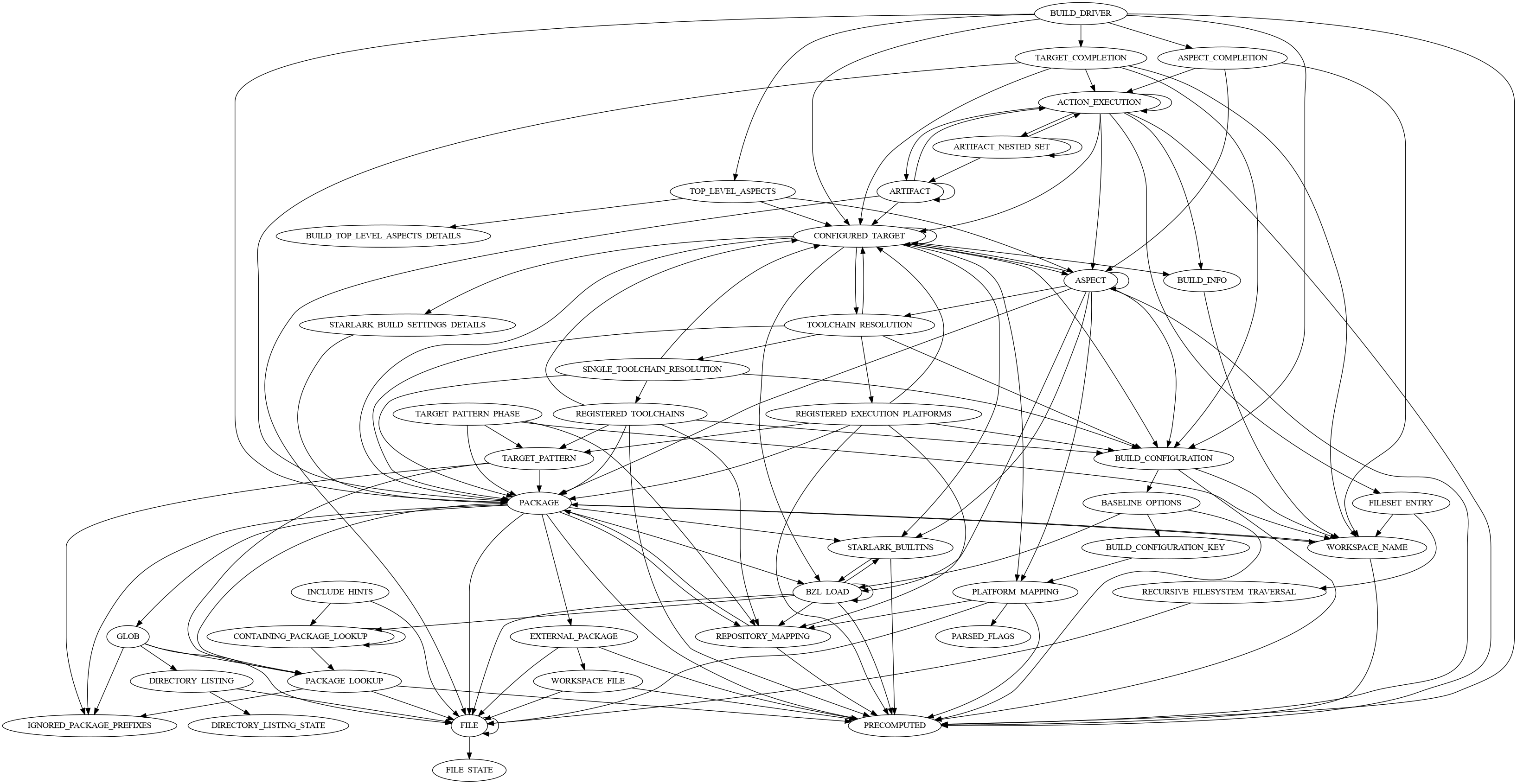
Mapping to Bazel concepts
This is high level summary of the key SkyFunction and SkyValue
implementations Bazel uses to perform a build:
- FileStateValue. The result of an
lstat(). For existent files, the function also computes additional information in order to detect changes to the file. This is the lowest level node in the Skyframe graph and has no dependencies. - FileValue. Used by anything that cares about the actual contents or
resolved path of a file. Depends on the corresponding
FileStateValueand any symlinks that need to be resolved (such as theFileValuefora/bneeds the resolved path ofaand the resolved path ofa/b). The distinction betweenFileValueandFileStateValueis important because the latter can be used in cases where the contents of the file are not actually needed. For example, the file contents are irrelevant when evaluating file system globs (such assrcs=glob(["*/*.java"])). - DirectoryListingStateValue. The result of
readdir(). LikeFileStateValue, this is the lowest level node and has no dependencies. - DirectoryListingValue. Used by anything that cares about the entries of
a directory. Depends on the corresponding
DirectoryListingStateValue, as well as the associatedFileValueof the directory. - PackageValue. Represents the parsed version of a BUILD file. Depends on
the
FileValueof the associatedBUILDfile, and also transitively on anyDirectoryListingValuethat is used to resolve the globs in the package (the data structure representing the contents of aBUILDfile internally). - ConfiguredTargetValue. Represents a configured target, which is a tuple
of the set of actions generated during the analysis of a target and
information provided to dependent configured targets. Depends on the
PackageValuethe corresponding target is in, theConfiguredTargetValuesof direct dependencies, and a special node representing the build configuration. - ArtifactValue. Represents a file in the build, be it a source or an
output artifact. Artifacts are almost equivalent to files, and are used to
refer to files during the actual execution of build steps. Source files
depends on the
FileValueof the associated node, and output artifacts depend on theActionExecutionValueof whatever action generates the artifact. - ActionExecutionValue. Represents the execution of an action. Depends on
the
ArtifactValuesof its input files. The action it executes is contained within its SkyKey, which is contrary to the concept that SkyKeys should be small. Note thatActionExecutionValueandArtifactValueare unused if the execution phase does not run.
As a visual aid, this diagram shows the relationships between SkyFunction implementations after a build of Bazel itself: