Bazel का पैरलल इवैल्युएशन और इंक्रीमेंटैलिटी मॉडल.
डेटा मॉडल
डेटा मॉडल में ये आइटम शामिल होते हैं:
SkyValue. इन्हें नोड भी कहा जाता है.SkyValuesनहीं बदले जा सकने वाले ऑब्जेक्ट होते हैं. इनमें बिल्ड के दौरान बनाया गया सारा डेटा और बिल्ड के इनपुट शामिल होते हैं. उदाहरण के लिए: इनपुट फ़ाइलें, आउटपुट फ़ाइलें, टारगेट, और कॉन्फ़िगर किए गए टारगेट.SkyKey. यहSkyValueका रेफ़रंस देने के लिए, नहीं बदला जा सकने वाला छोटा नाम होता है. उदाहरण के लिए,FILECONTENTS:/tmp/fooयाPACKAGE://foo.SkyFunction. यह नोड को उनकी कुंजियों और डिपेंडेंट नोड के आधार पर बनाता है.- नोड ग्राफ़. यह एक डेटा स्ट्रक्चर है, जिसमें नोड के बीच डिपेंडेंसी के संबंध की जानकारी होती है.
Skyframe. यह इंक्रीमेंटल इवैल्युएशन फ़्रेमवर्क का कोड नेम है. Bazel इसी पर आधारित है.
आकलन
बिल्ड के अनुरोध को दिखाने वाले नोड का आकलन करके, बिल्ड किया जाता है.
सबसे पहले, Bazel, टॉप-लेवल SkyKey की कुंजी के हिसाब से SkyFunction ढूंढता है. इसके बाद, फ़ंक्शन उन नोड के आकलन का अनुरोध करता है जिनकी ज़रूरत उसे टॉप-लेवल नोड का आकलन करने के लिए होती है. इससे अन्य SkyFunction कॉल जनरेट होते हैं. यह प्रोसेस तब तक चलती है, जब तक कि लीफ़ नोड तक न पहुंचा जाए. आम तौर पर, लीफ़ नोड वे होते हैं जो फ़ाइल सिस्टम में इनपुट फ़ाइलों को दिखाते हैं. आखिर में, Bazel को टॉप-लेवल SkyValue की वैल्यू, कुछ साइड इफ़ेक्ट (जैसे, फ़ाइल सिस्टम में आउटपुट फ़ाइलें) और बिल्ड में शामिल नोड के बीच डिपेंडेंसी का डायरेक्टेड एसाइक्लिक ग्राफ़ मिलता है.
अगर SkyFunction को पहले से यह पता नहीं है कि उसे अपना काम करने के लिए किन नोड की ज़रूरत है, तो वह कई बार SkyKeys का अनुरोध कर सकता है. इसका एक आसान उदाहरण, symlink के तौर पर दिखने वाले इनपुट फ़ाइल नोड का आकलन करना है: फ़ंक्शन, फ़ाइल को पढ़ने की कोशिश करता है. उसे पता चलता है कि यह symlink है. इसलिए, वह symlink के टारगेट को दिखाने वाले फ़ाइल सिस्टम नोड को फ़ेच करता है. हालांकि, यह खुद भी symlink हो सकता है. ऐसे में, ओरिजनल फ़ंक्शन को भी इसका टारगेट फ़ेच करना होगा.
कोड में, फ़ंक्शन को SkyFunction इंटरफ़ेस से दिखाया जाता है. साथ ही, इसे
सेवाएं SkyFunction.Environment नाम के इंटरफ़ेस से मिलती हैं. फ़ंक्शन ये काम कर सकते हैं:
env.getValueको कॉल करके, किसी दूसरे नोड के आकलन का अनुरोध करना. अगर नोड उपलब्ध है, तो उसकी वैल्यू दिखाई जाती है. नहीं तो,nullदिखाया जाता है. साथ ही, फ़ंक्शन से भीnullदिखाने की उम्मीद की जाती है. दूसरे मामले में, डिपेंडेंट नोड का आकलन किया जाता है. इसके बाद, ओरिजनल नोड बिल्डर को फिर से शुरू किया जाता है. हालांकि, इस बारenv.getValueकॉल सेnullके अलावा कोई वैल्यू मिलेगी.env.getValues()को कॉल करके, कई अन्य नोड के आकलन का अनुरोध करना. इससे भी वही काम होता है. हालांकि, डिपेंडेंट नोड का आकलन एक साथ किया जाता है.- कॉल किए जाने के दौरान, कंप्यूटेशन करना
- साइड इफ़ेक्ट होना. उदाहरण के लिए, फ़ाइल सिस्टम में फ़ाइलें लिखना. यह ध्यान रखना ज़रूरी है कि दो अलग-अलग फ़ंक्शन एक-दूसरे के काम में दखल न दें. आम तौर पर, राइट साइड इफ़ेक्ट (जिसमें डेटा, Bazel से बाहर की ओर जाता है) ठीक होते हैं. वहीं, रीड साइड इफ़ेक्ट (जिसमें डेटा, रजिस्टर की गई डिपेंडेंसी के बिना Bazel में अंदर की ओर जाता है) ठीक नहीं होते. ऐसा इसलिए, क्योंकि ये रजिस्टर न की गई डिपेंडेंसी होती हैं. इस वजह से, इंक्रीमेंटल बिल्ड गलत हो सकते हैं.
अच्छे से काम करने वाले SkyFunction लागू करने वाले फ़ंक्शन, डिपेंडेंसी का अनुरोध करने के अलावा किसी अन्य तरीके से डेटा ऐक्सेस नहीं करते. जैसे, सीधे फ़ाइल सिस्टम को पढ़कर. ऐसा इसलिए, क्योंकि इससे Bazel, पढ़ी गई फ़ाइल पर डेटा डिपेंडेंसी रजिस्टर नहीं करता. इस वजह से, इंक्रीमेंटल बिल्ड गलत हो सकते हैं.
जब किसी फ़ंक्शन के पास अपना काम करने के लिए ज़रूरी डेटा हो, तो उसे पूरा होने की जानकारी देने वाली null के अलावा कोई वैल्यू दिखानी चाहिए.
आकलन की इस रणनीति के कई फ़ायदे हैं:
- हर्मेटिसिटी. अगर फ़ंक्शन, अन्य नोड पर निर्भर रहकर ही इनपुट डेटा का अनुरोध करते हैं, तो Bazel इस बात की गारंटी दे सकता है कि अगर इनपुट की स्थिति एक जैसी है, तो एक जैसा डेटा मिलेगा. अगर सभी स्काई फ़ंक्शन, तय तरीके से काम करते हैं, तो इसका मतलब है कि पूरा बिल्ड भी तय तरीके से काम करेगा.
- सही और सटीक इंक्रीमेंटैलिटी. अगर सभी फ़ंक्शन के सभी इनपुट डेटा को रिकॉर्ड किया जाता है, तो Bazel, इनपुट डेटा में बदलाव होने पर सिर्फ़ उन नोड को अमान्य कर सकता है जिन्हें अमान्य करना ज़रूरी है.
- पैरललिज़्म. फ़ंक्शन, डिपेंडेंसी का अनुरोध करके ही एक-दूसरे के साथ इंटरैक्ट कर सकते हैं. इसलिए, एक-दूसरे पर निर्भर न रहने वाले फ़ंक्शन को एक साथ चलाया जा सकता है. साथ ही, Bazel इस बात की गारंटी दे सकता है कि नतीजे वही होंगे जो उन्हें क्रम से चलाने पर मिलते.
इंक्रीमेंटैलिटी
फ़ंक्शन, अन्य नोड पर निर्भर रहकर ही इनपुट डेटा को ऐक्सेस कर सकते हैं. इसलिए, Bazel, इनपुट फ़ाइलों से लेकर आउटपुट फ़ाइलों तक का पूरा डेटा फ़्लो ग्राफ़ बना सकता है. साथ ही, इस जानकारी का इस्तेमाल करके सिर्फ़ उन नोड को फिर से बिल्ड किया जा सकता है जिन्हें फिर से बिल्ड करना ज़रूरी है. जैसे, बदले गए इनपुट फ़ाइलों के सेट का रिवर्स ट्रांज़िटिव क्लोज़र.
खास तौर पर, इंक्रीमेंटैलिटी की दो रणनीतियां मौजूद हैं: बॉटम-अप और टॉप-डाउन. इनमें से कौनसी रणनीति सबसे सही है, यह इस बात पर निर्भर करता है कि डिपेंडेंसी ग्राफ़ कैसा दिखता है.
बॉटम-अप अमान्य करने की प्रोसेस के दौरान, ग्राफ़ बनने और बदले गए इनपुट के सेट की जानकारी मिलने के बाद, उन सभी नोड को अमान्य कर दिया जाता है जो बदले गए फ़ाइलों पर ट्रांज़िटिव तरीके से निर्भर होते हैं. यह तब सबसे सही होता है, जब टॉप-लेवल नोड को फिर से बिल्ड किया जाएगा. ध्यान दें कि बॉटम-अप अमान्य करने की प्रोसेस के लिए, यह पता लगाने के लिए कि पिछली बिल्ड की सभी इनपुट फ़ाइलों में बदलाव किया गया है या नहीं, उन पर
stat()चलाना ज़रूरी है. बदली गई फ़ाइलों के बारे में जानने के लिए,inotifyया इसी तरह के किसी अन्य मैकेनिज़्म का इस्तेमाल करके इसे बेहतर बनाया जा सकता है.टॉप-डाउन अमान्य करने की प्रोसेस के दौरान, टॉप-लेवल नोड के ट्रांज़िटिव क्लोज़र की जांच की जाती है. साथ ही, सिर्फ़ उन नोड को रखा जाता है जिनका ट्रांज़िटिव क्लोज़र साफ़ होता है. यह तब बेहतर होता है, जब नोड ग्राफ़ बड़ा हो, लेकिन अगली बिल्ड के लिए सिर्फ़ उसके छोटे सबसेट की ज़रूरत हो. बॉटम-अप अमान्य करने की प्रोसेस में, पहली बिल्ड के बड़े ग्राफ़ को अमान्य कर दिया जाएगा. वहीं, टॉप-डाउन अमान्य करने की प्रोसेस में, दूसरी बिल्ड के छोटे ग्राफ़ को ही अमान्य किया जाएगा.
Bazel, सिर्फ़ बॉटम-अप अमान्य करने की प्रोसेस का इस्तेमाल करता है.
Bazel, चेंज प्रूनिंग का इस्तेमाल करके, इंक्रीमेंटैलिटी को और बेहतर बनाता है: अगर किसी नोड को अमान्य किया जाता है, लेकिन फिर से बिल्ड करने पर यह पता चलता है कि उसकी नई वैल्यू, पुरानी वैल्यू के जैसी ही है, तो इस नोड में बदलाव की वजह से अमान्य किए गए नोड को "फिर से चालू" कर दिया जाता है.
उदाहरण के लिए, यह तब काम आता है, जब कोई व्यक्ति C++ फ़ाइल में कोई टिप्पणी बदलता है. ऐसे में, उससे जनरेट की गई .o फ़ाइल वही होगी. इसलिए, लिंकर को फिर से कॉल करने की ज़रूरत नहीं है.
इंक्रीमेंटल लिंकिंग / कंपाइलेशन
इस मॉडल की मुख्य सीमा यह है कि किसी नोड को अमान्य करने की प्रोसेस, पूरी तरह से या बिल्कुल नहीं वाली होती है: जब कोई डिपेंडेंसी बदलती है, तो डिपेंडेंट नोड को हमेशा शुरू से बिल्ड किया जाता है. भले ही, कोई बेहतर एल्गोरिदम मौजूद हो जो बदलावों के आधार पर नोड की पुरानी वैल्यू में बदलाव कर सके. यहां कुछ उदाहरण दिए गए हैं जिनमें यह काम आ सकता है:
- इंक्रीमेंटल लिंकिंग
- जब किसी JAR फ़ाइल में कोई एक क्लास फ़ाइल बदलती है, तो उसे शुरू से फिर से बिल्ड करने के बजाय, JAR फ़ाइल में ही बदलाव किया जा सकता है.
Bazel, इन चीज़ों को तय तरीके से क्यों नहीं करता, इसकी दो वजहें हैं:
- परफ़ॉर्मेंस में सीमित सुधार हुए.
- यह पुष्टि करना मुश्किल है कि म्यूटेशन का नतीजा, साफ़ तौर पर फिर से बिल्ड करने के नतीजे के जैसा ही होगा. साथ ही, Google, बिट-फ़ॉर-बिट दोहराए जा सकने वाले बिल्ड को अहमियत देता है.
अब तक, महंगे बिल्ड स्टेप को अलग-अलग हिस्सों में बांटकर और इस तरह, आंशिक रूप से फिर से आकलन करके, अच्छी परफ़ॉर्मेंस हासिल की जा सकती थी. उदाहरण के लिए, Android ऐप्लिकेशन में, सभी क्लास को कई ग्रुप में बांटा जा सकता है और उन्हें अलग-अलग डेक्स किया जा सकता है. इस तरह, अगर किसी ग्रुप में क्लास में कोई बदलाव नहीं किया जाता है, तो डेक्सिंग को फिर से करने की ज़रूरत नहीं होती.
Bazel के कॉन्सेप्ट से मैपिंग करना
यहां मुख्य SkyFunction और SkyValue लागू करने वाले फ़ंक्शन की खास जानकारी दी गई है. Bazel, बिल्ड करने के लिए इनका इस्तेमाल करता है:
- FileStateValue. यह
lstat()का नतीजा है. मौजूदा फ़ाइलों के लिए, फ़ंक्शन, फ़ाइल में हुए बदलावों का पता लगाने के लिए अतिरिक्त जानकारी भी कंप्यूट करता है. यह Skyframe ग्राफ़ में सबसे निचले लेवल का नोड है और इसकी कोई डिपेंडेंसी नहीं है. - FileValue. इसका इस्तेमाल, किसी फ़ाइल के असल कॉन्टेंट या रिज़ॉल्व किए गए पाथ के बारे में जानने के लिए किया जाता है. यह, इससे जुड़े
FileStateValueऔर उन सभी symlink पर निर्भर करता है जिन्हें रिज़ॉल्व करना ज़रूरी है. जैसे,a/bके लिएFileValueकोaके रिज़ॉल्व किए गए पाथ औरa/bके रिज़ॉल्व किए गए पाथ की ज़रूरत होती है.FileValueऔरFileStateValueके बीच का अंतर अहम है, क्योंकि इसका इस्तेमाल उन मामलों में किया जा सकता है जहां फ़ाइल के कॉन्टेंट की असल में ज़रूरत नहीं होती. उदाहरण के लिए, फ़ाइल सिस्टम ग्लोब (जैसे,srcs=glob(["*/*.java"])) का आकलन करते समय, फ़ाइल के कॉन्टेंट की कोई ज़रूरत नहीं होती. - DirectoryListingStateValue. यह
readdir()का नतीजा है.FileStateValueकी तरह, यह सबसे निचले लेवल का नोड है और इसकी कोई डिपेंडेंसी नहीं है. - DirectoryListingValue. इसका इस्तेमाल, किसी डायरेक्ट्री की एंट्री के बारे में जानने के लिए किया जाता है. यह, इससे जुड़े
DirectoryListingStateValueके साथ-साथ, डायरेक्ट्री के जुड़ेFileValueपर भी निर्भर करता है. - PackageValue. यह BUILD फ़ाइल के पार्स किए गए वर्शन को दिखाता है. यह, इससे जुड़ी
BUILDफ़ाइल केFileValueपर निर्भर करता है. साथ ही, यह ट्रांज़िटिव तरीके से किसी भीDirectoryListingValueपर भी निर्भर करता है जिसका इस्तेमाल पैकेज में ग्लोब को रिज़ॉल्व करने के लिए किया जाता है. पैकेज, इंटरनल तौर परBUILDफ़ाइल के कॉन्टेंट को दिखाने वाला डेटा स्ट्रक्चर होता है. - ConfiguredTargetValue. यह कॉन्फ़िगर किए गए टारगेट को दिखाता है. यह टारगेट के विश्लेषण के दौरान जनरेट की गई कार्रवाइयों के सेट और डिपेंडेंट कॉन्फ़िगर किए गए टारगेट को दी गई जानकारी का टपल होता है. यह, इससे जुड़े टारगेट के
PackageValue, डायरेक्ट डिपेंडेंसी केConfiguredTargetValues, और बिल्ड कॉन्फ़िगरेशन को दिखाने वाले खास नोड पर निर्भर करता है. - ArtifactValue. यह बिल्ड में मौजूद किसी फ़ाइल को दिखाता है. यह सोर्स या आउटपुट आफ़्टिफ़ैक्ट हो सकता है. आफ़्टिफ़ैक्ट, फ़ाइलों के लगभग बराबर होते हैं. इनका इस्तेमाल, बिल्ड स्टेप के असल एक्ज़ीक्यूशन के दौरान फ़ाइलों को रेफ़र करने के लिए किया जाता है. सोर्स फ़ाइलें, इससे जुड़े नोड के
FileValueपर निर्भर करती हैं. वहीं, आउटपुट आफ़्टिफ़ैक्ट, उस कार्रवाई केActionExecutionValueपर निर्भर करते हैं जिससे आफ़्टिफ़ैक्ट जनरेट होता है. - ActionExecutionValue. यह किसी कार्रवाई के एक्ज़ीक्यूशन को दिखाता है. यह, अपनी इनपुट फ़ाइलों के
ArtifactValuesपर निर्भर करता है. यह जिस कार्रवाई को एक्ज़ीक्यूट करता है वह इसकी SkyKey में शामिल होती है. यह इस कॉन्सेप्ट के उलट है कि SkyKey छोटी होनी चाहिए. ध्यान दें कि अगर एक्ज़ीक्यूशन फ़ेज़ नहीं चलता है, तोActionExecutionValueऔरArtifactValueका इस्तेमाल नहीं किया जाता.
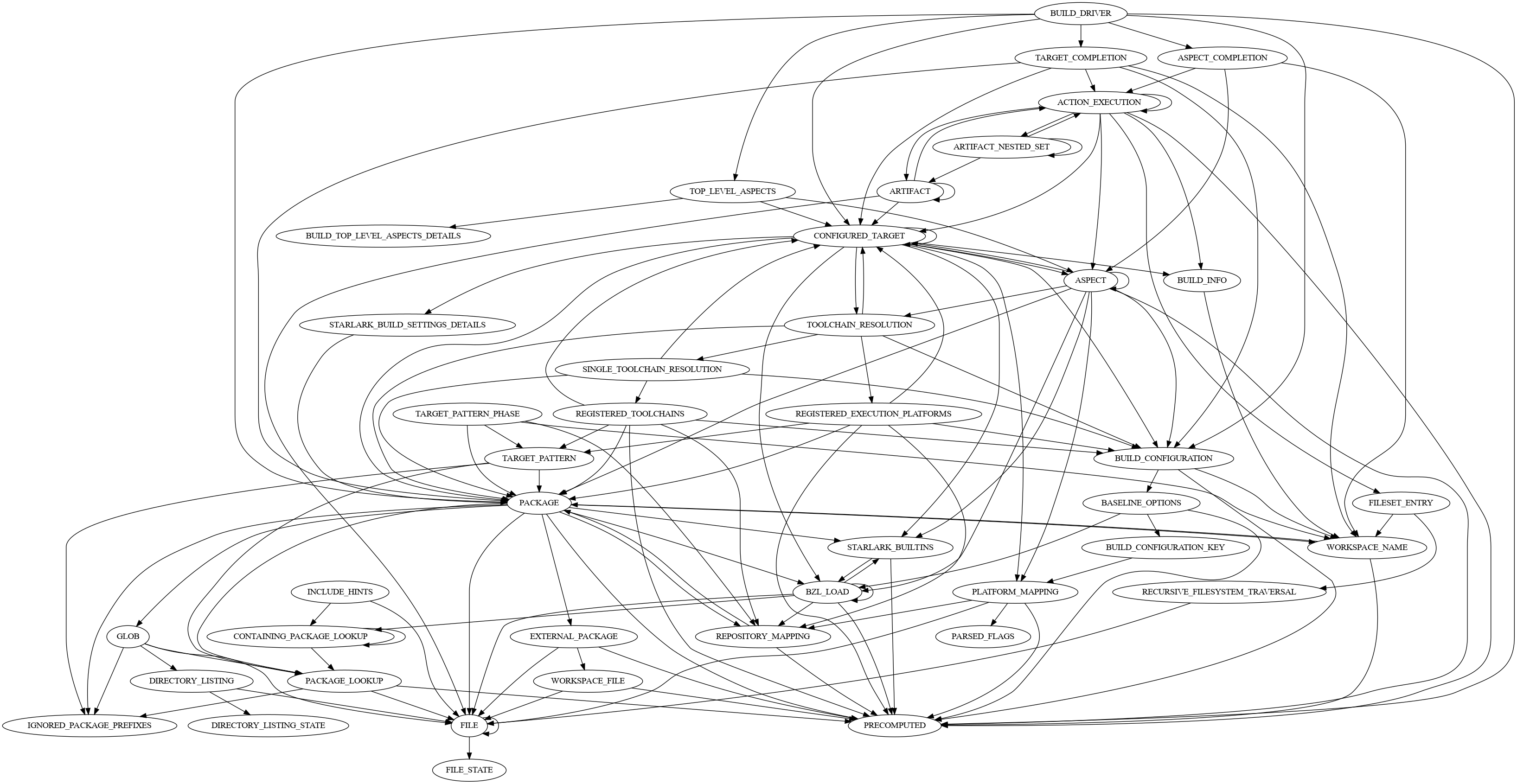
विज़ुअल सहायता के तौर पर, इस डायग्राम में SkyFunction लागू करने वाले फ़ंक्शन के बीच संबंध दिखाए गए हैं. यह जानकारी, Bazel के बिल्ड के बाद की है: